
In 2017, I had the opportunity to present the "Architecting Data Lakes on AWS" session at the AWS India Summit. My team at Hifx had built multiple Data & ML pipelines for a leading media conglomerate the previous year, and the session highlighted the underlying architecture that powered all these use-cases.
Five years have passed since, and the cloud data technology landscape has undergone significant changes, and I thought it would be a good exercise to see how the data stack/architecture would look like if we are building this today.
Before diving into the re-architecture, let me shed some more light on the platform itself and the business problems it solved back in 2016.
Circa 2016: Cloud Data Platform To Support Data Analytics and AI
We were tasked with building a data platform to help the customer make better product decisions based on behavioural insights and improve the user experience of their content portals through recommendation engines.
Challenges
The customer has dozens of digital properties/products and many independently managed collections of data, leading to data silos and inconsistent KPIs/metrics. Having no single source of truth led to difficulties in identifying the type of data available, governing access and gleaning insights. In addition, the volume and velocity of data were increasing rapidly, and the existing solutions were not scaling/performing well. These challenges led to business/product management teams not getting any value from their data.
Lens: Cloud Data Platform
I was lucky to have a great team of brilliant engineers (albeit small). We built a solution called Lens. Lens aided better business agility, better user experience, consistent KPI measurement, and the ability to run targeted mobile push and email campaigns.
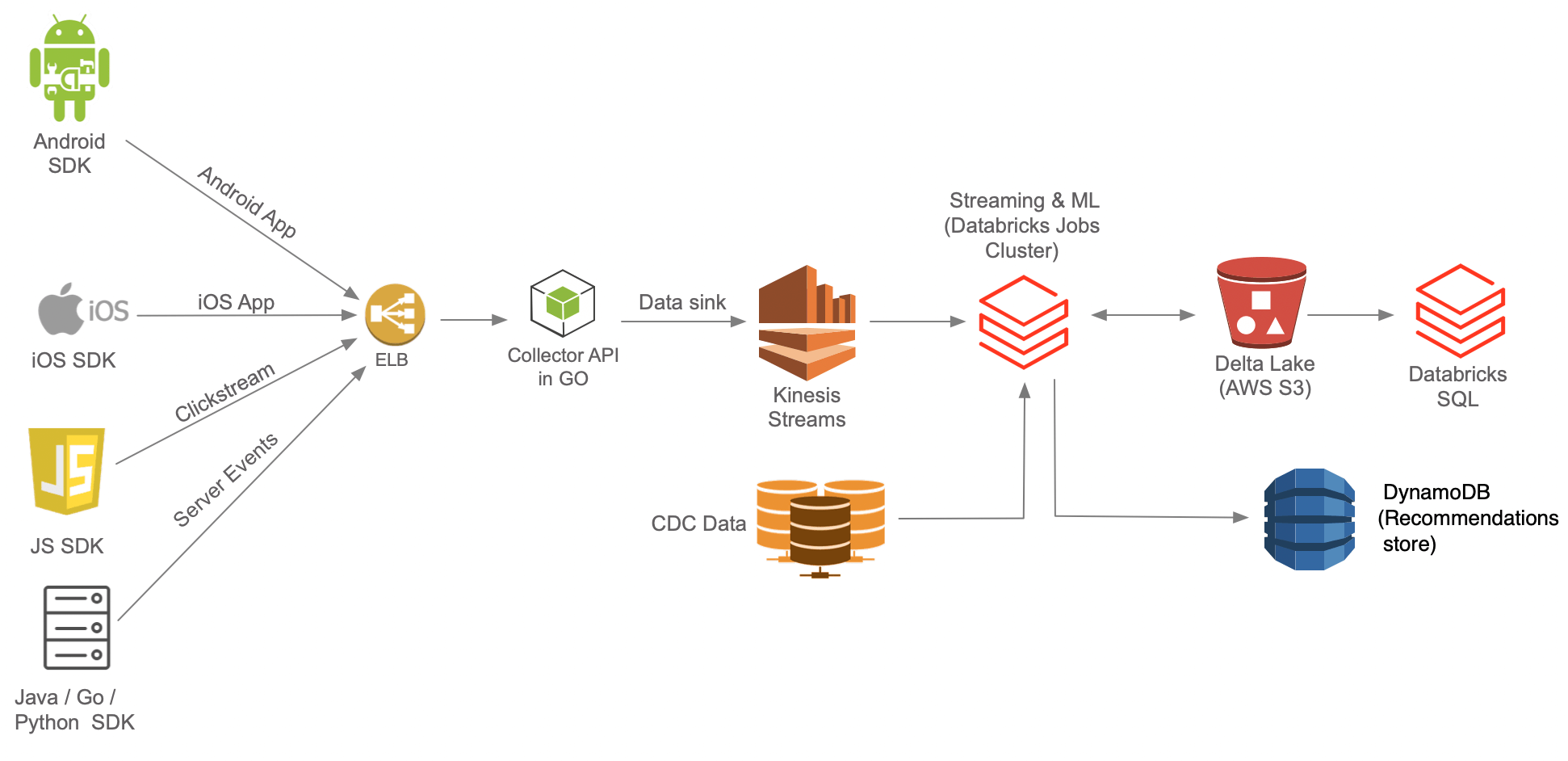
Lens had four major foundational building blocks - Ingestion, Storage, Processing and Serving
Ingestion & Storage Layer
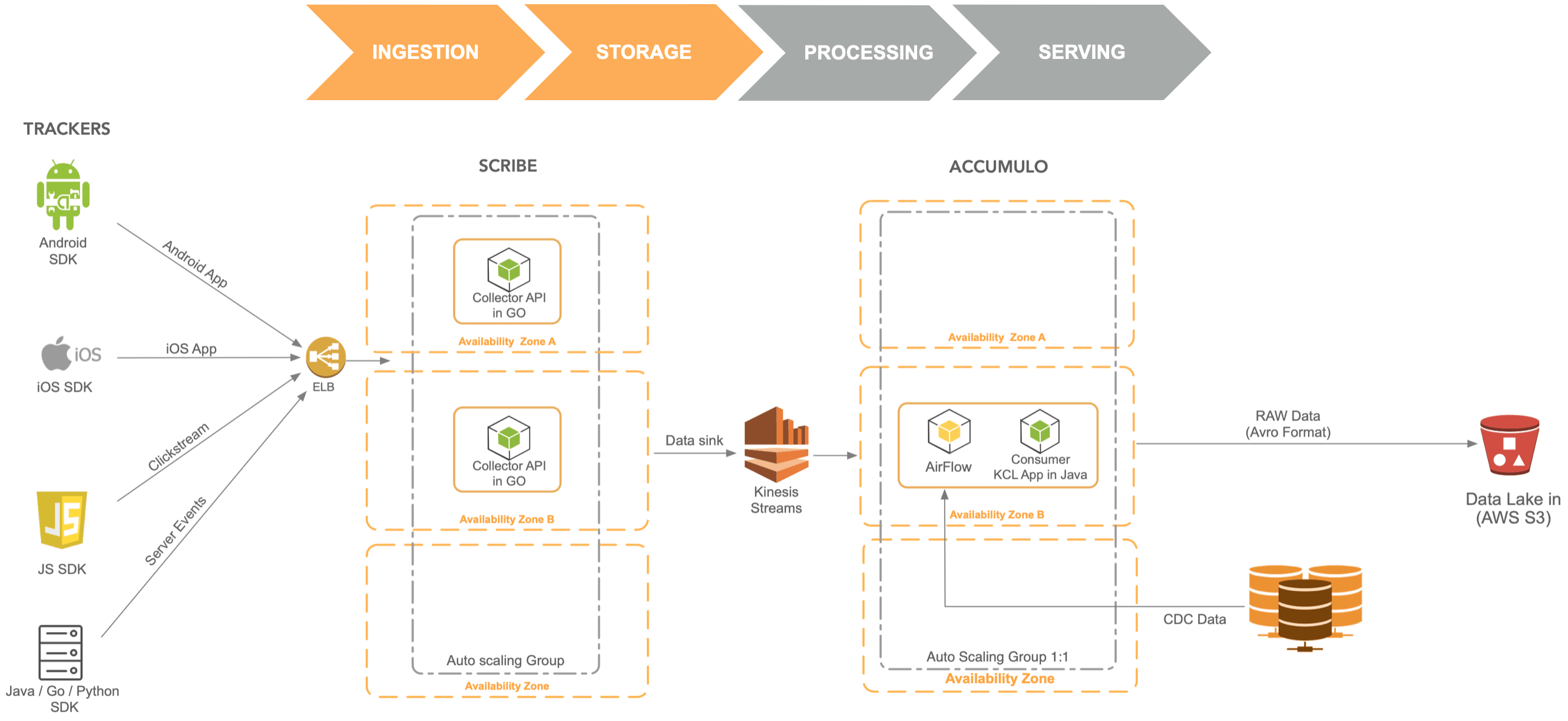
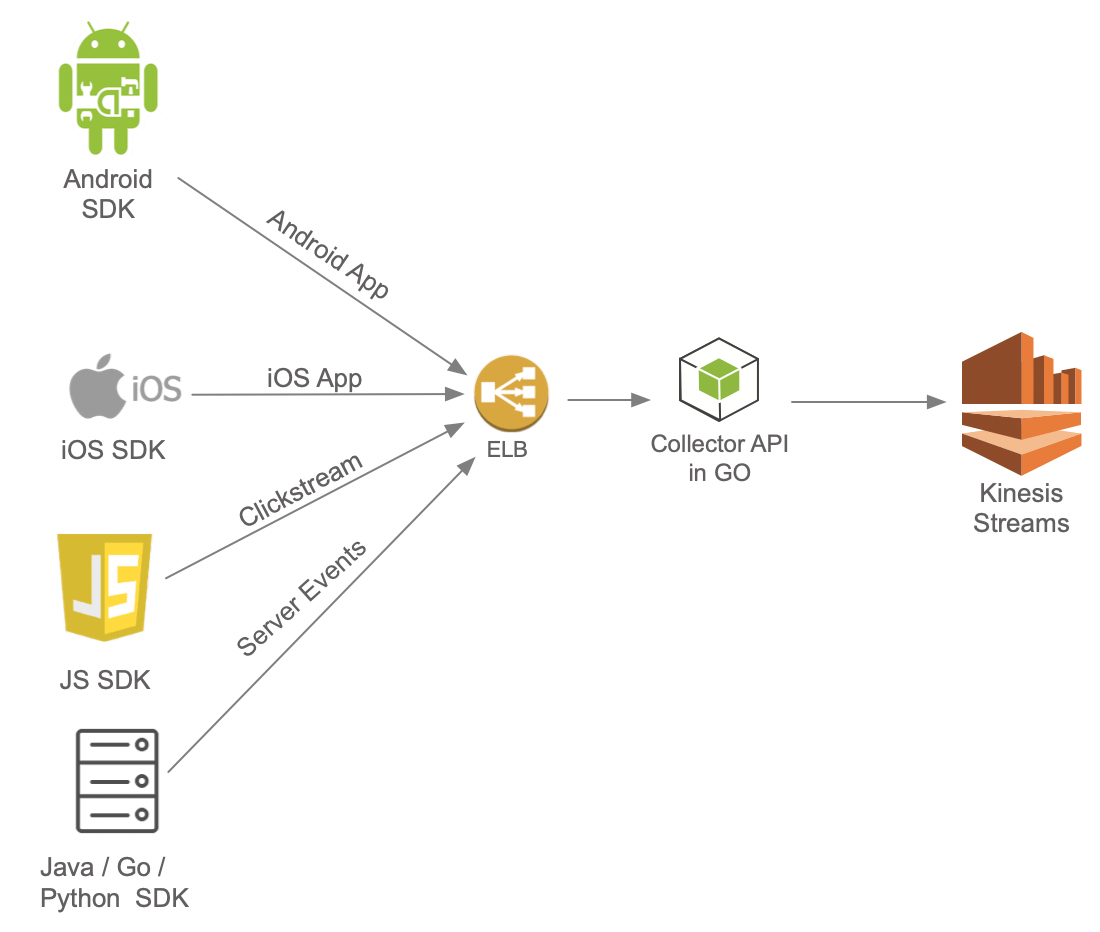
The Ingestion layer consists of Trackers, which are SDKs for various applications and platforms to send event data. For each of these SDKs, the team did a great job ensuring that instrumentation does not affect page/application performance (async API calls) and data is not lost due to poor network connectivity(local caching & intelligent retries).
Scribe collects data from the trackers and writes them to Kinesis Streams. The API was written in Go and designed for high concurrency, low latency (p99 low double-digit ms even at thousands of writes per second) and horizontal scalability.
The component responsible for reading data from Kinesis Streams is Acccumulo. The data consumer application makes use of Kinesis Client Library, performs rudimentary data quality checks and buffers the events and uploads the batches as Avro files to the Data Lake in S3. KCL is a convenience library that provides the following functionalities out of the box
- Load balancing across multiple consumer instances
- Responding to consumer instance failures
- Checkpointing processed records
- React to resharding
Jobs in Airflow pull data from Mysql & other stores and load them to the data lake.
Processing & Serving Layer
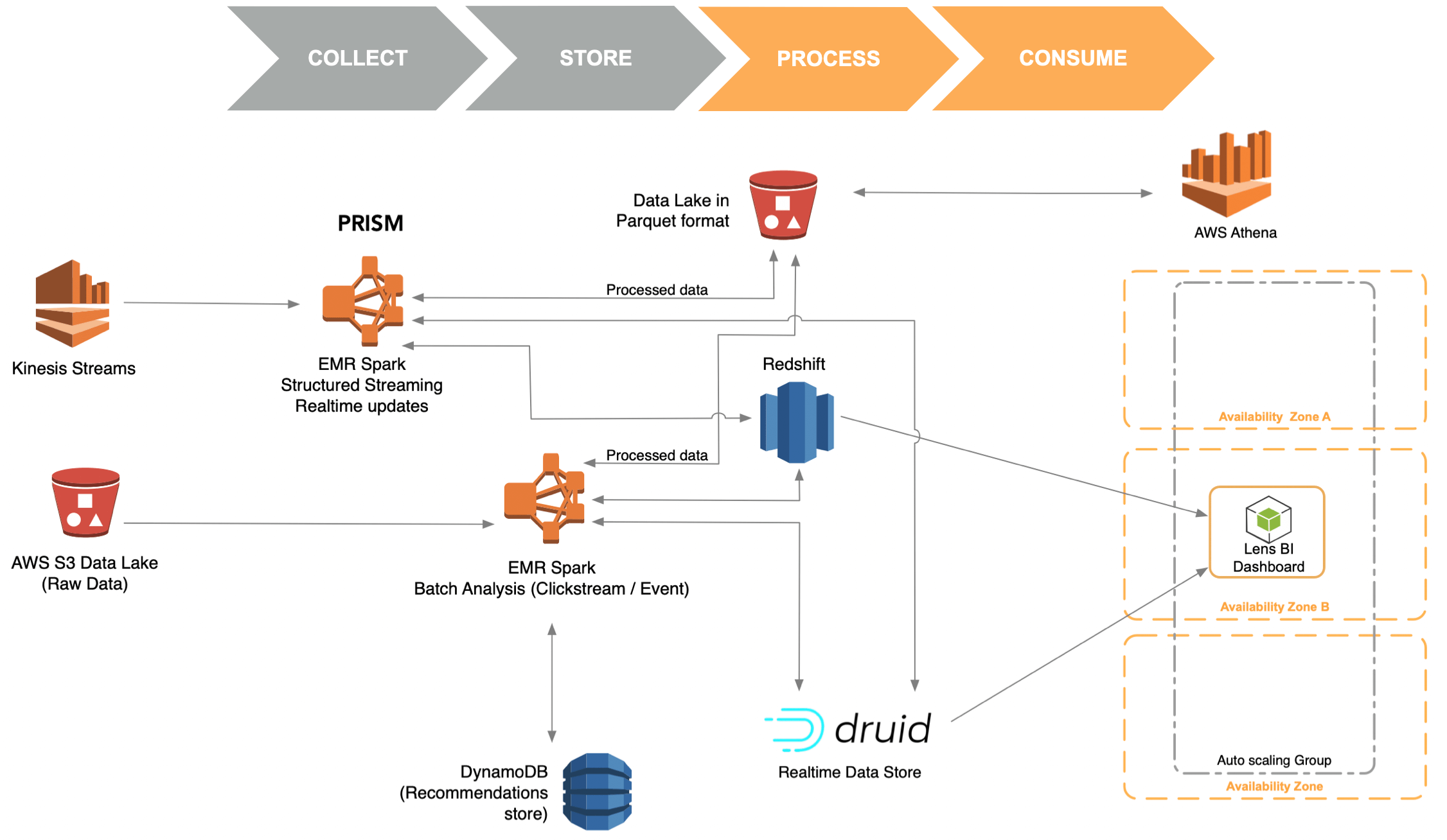
Prism is a metadata/configuration-driven framework for processing data, and it uses Apache Spark as the underlying unified engine for both batch and streaming workloads. Airflow is used to schedule and monitor workflows. Prism generates data for tracking KPIs and performs funnel, pathflow, retention and affinity analysis. It also includes machine learning workloads that generate content recommendations and predictions.
The Serving Layer consists of DynamoDB, Druid, Redshift and Athena. DynamoDB serves as the recommendations data store, which gets populated by the recommendation pipeline. This data powers the Content Recommendation API used by mobile applications and consumer-facing websites. Druid is the near-realtime data store that powers the dashboard used by various editors to decide which content to promote and which story to focus on. Redshift powers the queries behind functionalities like search insights, funnels, event segmentation and stickiness/retention reports.
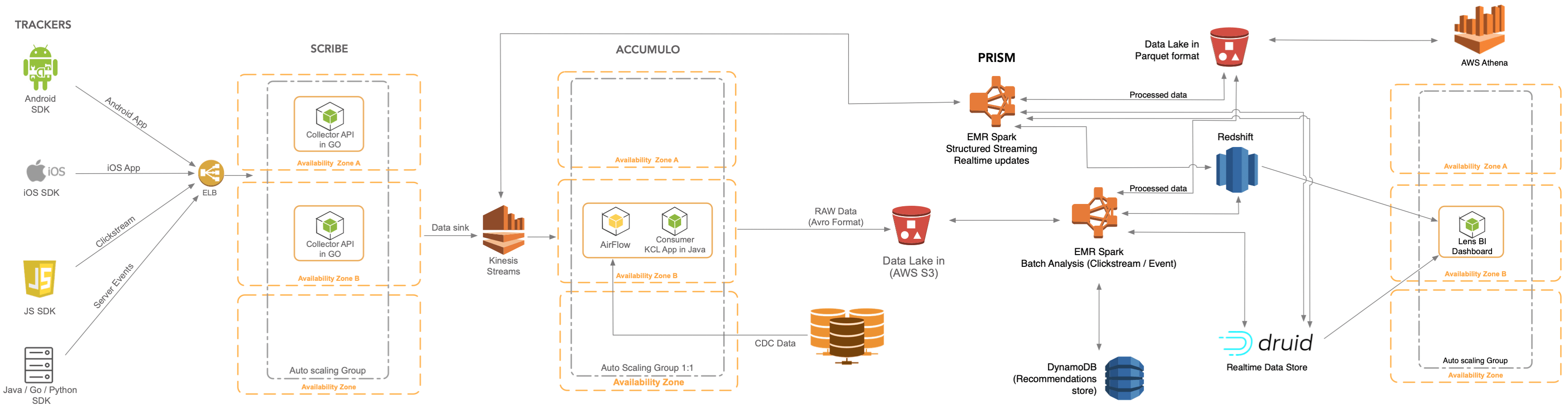
The high-level architecture of Lens that combines all four layers is shown below.
2021: Rethinking Cloud Data Architecture
There is increasing consensus that data is eating the software that is eating the world. As every company is becoming a data company, it also amplifies some of the challenges. In addition to the requirements discussed in the first section, organizations today need to navigate concerns around
- Data Quality, Reliability and Accuracy
- Data Sharing
- Data Discovery & Lineage
- Data Governance
- Data Observability
I’ll reserve that discussion for another blog post and focus this one on high-level architecture.
Accidental vs Essential Complexity - Does it have to be this hard?
In his classic 1986 essay, No Silver Bullet, Fred Brooks argues that difficulties/complexities in software could be divided into two
- Essential - difficulties inherent in the nature of software and
- Accidental - difficulties that today attend its production but are not inherent.
He goes on to explain how high-level languages, time-sharing, and unified programming environments have been fruitful in solving accidental complexities.
From the complexity comes the difficulty of communication among team members, which leads to product flaws, cost overruns, schedule delays. From the complexity comes the difficulty of enumerating, much less understanding, all the possible states of the program, and from that comes the unreliability. From complexity of function comes the difficulty of invoking function, which makes programs hard to use. From complexity of structure comes the difficulty of extending programs to new functions without creating side effects. From complexity of structure come the unvisualized states that constitute security trapdoors.
Fred Brooks also argues that most of the complexity in software is essential in nature. However (having worked with many enterprises to rearchitect/modernize their data stack over the last few years), anecdotal evidence suggests that accidental complexity dominates a lot of solutions today, including the one we discussed above, and there is room for improvement.
In the following sections, I will attempt to revisit the original building blocks of the solution and see how it would look if it is getting built today.
Ingestion Layer
I’m a big believer in open source and have built most of my career using open source solutions. Back in 2016, when we were building Tracker SDK and collectors - there weren’t many suitable OSS tools meeting the requirements. However, the last few years have witnessed many OSS innovations occurring in almost every layer in the cloud data stack. One such tool worth taking a deeper look at is rudder-server and rudder-sdks for js, ios and android .
Rudder’s design has significant differences from the trackers and API we built a while back. By architecting the APIs to be stateless, we were able to get low latency (p99 low double-digit ms even at thousands of writes per second) and horizontal scalability. By choosing to offload transformation logic to data processing later and adhering to SoC design principle, we ensured that events reached the messaging infrastructure ( kafka/kinesis) with minimal latency and almost no data loss. All the transformation/enrichment /metrics-calculation logic were in the processing (Prism) layer
This brings up an interesting build vs buy question.
Quoting Fred Brooks again
The most radical possible solution for constructing software is not to construct it at all…The key issue, of course, is applicability. Can I use an available off-the-shelf package to perform my task?
To quote Will Larson (Btw, I recommend his book Staff Engineer)
In the build versus buy decision, most companies put the majority of their energy into identifying risk, which has its place, but often culminates in a robust not invented here culture that robs the core business of attention. To avoid that fate, it’s important to spend at least as much time on the value that comes from buy decisions.
So - If I were to redesign this layer all over again, I would spend some time understanding the latency/throughput offered by rudderstack and focus on the value it would provide before building something similar from the ground up. There is wisdom in striving to be a 0.1x engineer.
Storage & Processing Layer
While the storage & processing components built-in 2016 addressed the challenges, it also suffers from the drawbacks of the classic lambda architecture. KCL application forces the choice between the liveliness of data and the small files problem. Schema Registry is an additional component to maintain with high availability adding operational burden. Apache Spark Structured Streaming and Delta Lake offers a much simpler and more optimized solution. Instead of using a combination of batch and streaming jobs with Avro and Parquet as data lake formats, Delta Architecture offers an entirely different approach to ingesting, processing, storing, and managing data focused on simplicity. All the processing and enrichment of data from Bronze (raw data) to Silver (filtered) to Gold (fully ready to be used by analytics, reporting, and data science) happens within Delta Lake.
The following videos explain how lakehouse with delta lake adds simplicity, performance, and reliability and its advantages over lambda architecture.
- Beyond Lambda: Introducing Delta Architecture - By Denny Lee
- Delta Lake: Reliability and Data Quality for Data Lakes and Apache Spark by Michael Armbrust
It is great to see many other open data lake table formats also evolving because it underpins the belief that the lakehouse architecture pattern is a great way to build future-friendly data platforms. I will reserve a comparison of delta lake with other open data lake formats and a comparison of different data serialization formats like protobuf, thrift & avro for another post
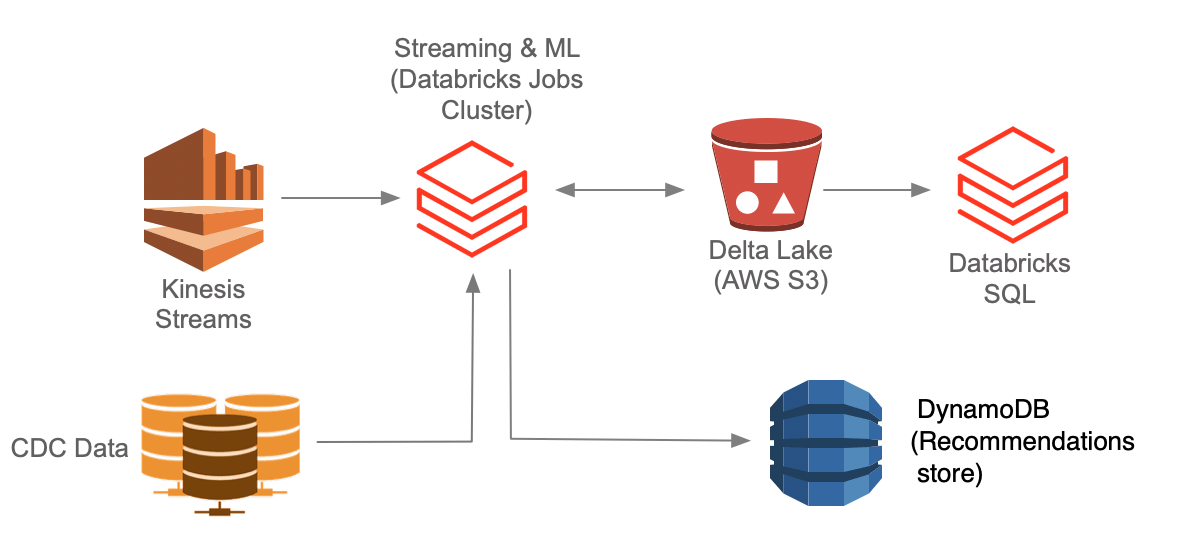
Serving Layer
DynamoDB is still a good choice for the recommendations datastore as long as we work around its limits. Adding Amazon DynamoDB Accelerator (DAX) for the Content Recommendation API could help keep the provisioned throughput down for DynamoDB while maintaining lower latencies.
With the Photon engine providing better price/performance for all the data in the data lake - Databricks SQL clusters eliminates the need for the additional hop of copying data over to a data warehouse.
For the real-time data store, several solutions have emerged in the last few years, like Pinot and Clickhouse in addition to Druid. Now - in practice, the definition of the term real-time varies from industry to industry and use case to use case.
Real-time for an editor in a newsroom is to know the trending topic/article in thirty seconds to one minute. However, the latency requirements of a use-case for real-time ad targeting or game leaderboards could be very different.
There are a small subset of use-cases served by niche real-time data stores with features like pre-aggregation and materialized views. For this use-case, however, the requirements would be met if queries are returned in lower single-digit seconds. Given the newer intelligent workload management features and the fact that we could avoid copying data over to another system - the Photon engine engine in Databricks is a viable option.
You Don’t Need to Compromise Simplicity For Performance & Reliability
We went through some design considerations applicable while architecting a cloud data stack. Instead of building something from scratch, the Ingestion layer would be kept lightweight - preferably an OSS-based solution (that meets the requirements). For the Processing layer, instead of having separate batch and streaming components, Prism could be designed to use delta lake and unify them. Regarding language choice for Prism- I’d advocate for writing it in Python instead of Scala. For the Serving Layer, the Lakehouse approach with the Photon Engine eliminates the need to duplicate datasets to multiple locations.
The resulting solution is a much simpler stack to own and operate with a lower TCO.
PS: Thank you Rafeeq Mohamed, Mahija Abdulkader and John O’Dwyer for being my sounding board